Elm in Wasm: Custom types and extensible Records
In the last post we discussed Elm's built-in types: Int, Float, Char, String, List, and tuples. This time let's look at user-defined "custom" types and extensible Records!
This is part of a series about porting the Elm language to WebAssembly. It's a project I am doing as a hobbyist, not an official project by the core team.
Custom types
Elm Custom types are collections that the Elm programmer can define. They can have different variants, each with a "constructor" to identify it. And each constructor can contain some collection of values.
Let's take a simple example where one constructor takes no parameters and the other takes two. We'll then look at how to implement this as a byte-level data structure.
type MyCustomType
= Ctor0
| Ctor1 Int Char
myCtor1 = Ctor1 42 'x'
Each value of this type will need
- A value header with some runtime metadata (which helps with GC and some built-in operators like
==) - Some way of identifying the associated constructor
- The contained values, if any
An implementation is shown in the diagram below. (Each small box represents a 32-bit value.)
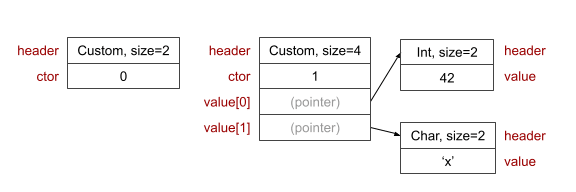
The ctor field identifies the constructor variant of the type the value is. It value needs to be unique within a given type so that we can implement pattern matching. It doesn't need to be unique within the program because the Elm compiler ensures that we can never compare or pattern-match values of different types. (Though with 32 bits, we get around 4 billion constructors. So it's easy to make them globally unique, and it can be handy for debugging).
Variants that take parameters will have an associated constructor function, generated by the compiler.
Variants that take no parameters are static constants in the program, without a constructor function. There only needs to be one instance of the value per program. For example the list [Ctor0, Ctor0, Ctor0] would just contain three pointers to the same memory address where Ctor0 is located.
Unit
The Unit type is just like a custom type with a single constructor. It has its own special symbol () in Elm source code but it's otherwise equivalent to the definition below.
type Unit = Unit
Bool
Bool follows the same structure as custom types. It has two constructors:
type Bool
= True
| False
True and False are constructors without any parameters, so they can be global constant values, defined once per program at a fixed memory location.
An alternative way to implement
Boolwould be to just use the integers 1 and 0, and that would make a lot of code more efficient. However a complication arises when we want to create something like aList Bool. Normally aConscell in aListcontains a pointer to itsheadvalue. But now we're saying thatTrueis not a pointer, it's just a literal number! That means theheadof aConscell might be a pointer or it might be just an integer, it depends! We need infrastructure in the compiler and runtime to resolve that ambiguity. Almost all mature language runtimes do this, but my project is not quite that mature yet.
Extensible Records
Records are one of the most interesting parts of Elm's type system. In the following code, each function takes an extensible record type, which allows us to pass it a value of either type Rec1 or Rec2. But values are either definitely of type Rec1, or definitely of type Rec2.
type alias Rec1 = { myField : Int }
type alias Rec2 = { myField : Int, otherField : Bool }
sumMyField : List { r | myField : Int } -> Int
sumMyField recList =
List.sum .myField recList -- accessor .myField is an Elm function
incrementMyField : { r | myField : Int } -> r
incrementMyField r =
{ r | myField = r.myField + 1 } -- record update expression
The basic operators that work on extensible record types are accessor functions and update expressions. In both cases we need to find the relevant field in a particular record before we can do anything with it. So there needs to be some mechanism to look up the position of a field within a record.
Field IDs as integers
In Elm source code, fields are human-readable labels for parameters of a Record. But they can be represented in more efficient ways. For example the 0.19 compiler in --optimize mode converts field names to unique shortened names in the generated JavaScript.
For a lower-level target like Wasm, we can transform field names to integer IDs rather than shortened names.
There are two ways to do this
- Copy and modify the compiler code for generating short names and generate integers intead
- If we're targeting an intermediate language, let it generate integer values for us. For example my C implementation emits an
enumlike this:
enum field {
FIELD_init,
FIELD_subscriptions,
FIELD_update,
FIELD_view,
};
All C code refers to Record fields using the enum members, which the C compiler later transforms to numbers. This approach helps with readability of the C code when debugging the compiler.
Record implementation
Let's see how we can represent records, using the following value as an example
type alias ExampleRecordType =
{ field123 : Int
, field456 : Char
}
myRecord : ExampleRecordType
myRecord =
{ field123 = 42
, field456 = 'x'
}
This can be represented by the collection of low-level structures below. For illustration, we assume the compiler has converted the field name field123 to the integer 123, and field456 to 456. Integers and pointers are 32 bits and so take up 1 size unit, Floats are 64 bits and take up 2 size units.

The FieldGroup data structure is an array of integers with a size. It is a static piece of metadata about the record type ExampleRecordType. My fork of the Elm compiler generates one instance for each record type, and populates it with the relevant integer field IDs. All records of the same type point to a single shared FieldGroup. The FieldGroup does not need a header field since it can never be confused with any other type. It only be accessed through a Record and is not garbage-collected since it's static data.
The Record itself is a collection of pointers, referencing its FieldGroup and its parameter values. The value pointers are arranged in the same order as the field IDs in the FieldGroup, so that accessor functions and update expressions can easily find the value corresponding to a particular field ID.
Field access
To implement an expression like myRecord.field123, the algorithm is as follows
- Look at the
fieldgroupproperty ofmyRecord - Follow the pointer to the
FieldGroupinstance - Search for the field ID
123, finding it at position0 - Look up the value at position
0inmyRecorditself
Accessor functions
An Elm accessor function is a special function that looks up a particular field name.
.field123 myRecord -- 42
Here, .field123 is a function that will access field123 of any record that contains it.
The simplest way to implement this is to define a kernel function that can access any Record field by ID, taking the field ID as the first parameter. Then we can just use partial application to specialise it to a specific field in the generated code.
If you're interested in more details, check out the full source, and perhaps read my previous post on Elm functions in Wasm to see how partial application is implemented.
Update expressions
Elm update expressions look like this:
updatedRecord =
{ originalRecord
| updatedField1 = newValue1
, updatedField2 = newValue2
}
In Elm 0.19 this is implemented by a JavaScript function that clones the old record, and then updates each of the selected fields in the new record.
function _Utils_update(oldRecord, updatedFields) {
var newRecord = {};
for (var key in oldRecord) {
newRecord[key] = oldRecord[key];
}
for (var key in updatedFields) {
newRecord[key] = updatedFields[key];
}
return newRecord;
}
We can do something similar in C as follows:
Record* Utils_update(Record* r, int n_updates, int fields[], void* values[]) {
Record* r_new = clone(r);
for (int i=0; i < n_updates; ++i) {
int field_pos = fieldgroup_search(r_new->fieldgroup, fields[i]);
r_new->values[field_pos] = values[i];
}
return r_new;
}
I've left out the details of clone and fieldgroup_search but they pretty much do what you'd expect. Feel free to take a look at the full source code, which includes tests that mimic generated code from the compiler.
Records in similar languages
OCaml has records, but not extensible record types. That means a given field always refers to the same position in a record type, so there's no need to search for it at runtime. All field names can safely be transformed into position offsets at compile time.
Haskell has extensible records, and the original paper on them is here. The focus is very much on trying to make the record system backwards-compatible with Haskell's pre-existing types, which were all positional rather than named. Unfortunately this means that most of their design decisions were driven by a constraint that Elm just doesn't have, so I didn't find it directly useful.
However the FieldGroup concept is very much inspired by the InfoTable that is generated for every type in a Haskell program.