Should Frontend Devs Care About Performance??

I was recently talking to an architect at Amazon and he made a very interesting comment to me. We were talking about the complexity of a given algorithm (discussed in Big-O notation), and before we even got too far into the explanation, he said:
I mean, it's not like we need to worry too much about this. After all, we're frontend devs!
I found this admission to be extremely refreshing, and it was entirely unexpected coming from someone in the Ivory Tower that is Amazon. It's something that I've always known. But it was still really nice to hear it coming from someone working for the likes of a FAANG company.
You see, performance is one of those subjects that programmers love to obsess about. They use it as a Badge of Honor. They see that you've used JavaScript's native .sort() method, then they turn up their nose and say something like, "Well, you know... That uses O(n log(n)) complexity." Then they walk away with a smug smirk on their face, as though they've banished your code to the dustbin of Failed Algorithms.
Smart Clients vs. Dumb Terminals
The terms "smart client" and "dumb terminal" have fallen somewhat by-the-wayside in recent decades. But they're still valid definitions, even in our modern computing environments.
Mainframe Computing
Way back in the Dark Ages, nearly all computing was done on massive computers (e.g., mainframes). And you interacted with those computers by using a "terminal". Those terminals were often called "dumb terminals" because the terminal itself had almost no computing power of its own. It only served as a way for you to send commands to the mainframe and then view whatever results were returned from... the mainframe. That's why it was called "dumb". Because the terminal itself couldn't really do much of anything on its own. It only served as a portal that gave you access to the mainframe.
For those who wrote mainframe code, they had to worry greatly about the efficiency of their algorithms. Because even the mainframe had comparatively-little computing power (by today's standards). More importantly, the mainframe's resources were shared by anyone with access to one of the dumb terminals. So if 100 people, sitting at 100 dumb terminals, all sent resource-intensive commands at the same time, it was pretty easy to crash the mainframe. (This is also why the allocation of terminals was very strict, and even those who had access to mainframe terminals often had to reserve time on them.)
PC Computing
With the PC explosion in the 80s, suddenly you had a lot of people with a lot of computing power (relatively speaking) sitting on their desktop. And most of the time, that computing power was underutilized. Thus spawned the age of "smart clients".
In a smart client model, every effort is made to allow the client to do its own computing. It only communicates back to the server when existing data must be retrieved from the source, or when new/updated data must be sent back to that source. This offloaded a great deal of work off of the mainframe, down to the clients, and allowed for the creation of much more robust applications.
A Return To Mainframe Computing (Sorta...)
But when the web came around, it knocked many applications back into a server/terminal kinda relationship. That's because those apps appeared to be running in the browser, but the simple fact is that early browser technology was incapable of really doing much on its own. Early browsers were quite analogous to dumb terminals. They could see data that was sent from the server (in the form of HTML/CSS). But if they wanted to interact with that data in any meaningful way, they needed to constantly send their commands back to the server.
This also meant that early web developers needed to be hyper-vigilant about efficiency. Because even a seemingly-innocuous snippet of code could drag your server to its knees if your site suddenly went viral and that code was being run by hundreds (or thousands) of web surfers concurrently.
This could be somewhat alleviated by deploying more robust backend technologies. For example, you could deploy a web farm that shared the load of requests for a single site. Or you could write your code in a compiled language (like Java or C#), which helped (somewhat) because compiled code typically runs faster than interpreted code. But you were still bound by the limits that came from having all of your public users hitting a finite set of server/computing resources.

The Browser AS Smart Client
I'm not going to delve into the many arguments for-or-against Chrome. But one of its greatest contributions to web development is that it was one of the first browsers that was continually optimized specifically for JavaScript performance. When this optimization was combined with powerful new frameworks like jQuery (then Angular, then React, then...), it fostered the rise of the frontend developer.
This didn't just give us new capabilities for frontend functionality, it also meant that we could start thinking, again, in terms of the desktop (browser) being a smart client. In other words, we didn't necessarily have to stay up at night wondering if that one aberrant line of code was going to crash the server. At worst, it might crash someone's browser. (And don't get me wrong, writing code that crashes browsers is still a very bad thing to do. But it's farrrrr less likely to occur when the desktop/browser typically has all those unused CPU cycles just waiting to be harnessed.)
So when you're writing, say, The Next Great React App, how much, exactly, do you even need to care about performance?? After all, the bulk of your app will be running in someone's browser. And even if that browser is running on a mobile device, it probably has loads of unleveraged processing power available for you to use. So how much do you need to be concerned about the nitty-gritty details of your code's performance? IMHO, the answer is simple - yet nuanced.
Care... But Not That Much
Years ago, I was listening to a keynote address from the CEO of a public company. Public companies must always (understandably) have one eye trained on the stock market. During his talk, he posed the question: How much do I care about our company's stock price? And his answer was that he cared... but not that much. In other words, he was always aware of the stock price. And of course, he was cognizant of the things his company could do (or avoid doing) that would potentially influence their stock price. But he was adamant that he could not make every internal corporate decision based upon one simple factor - whether or not it would juice the stock price. He had to care about the stock price, because a tanking stock price can cause all sorts of problems for a public company. But if he allowed himself to focus, with tunnel vision, on that stock price, he could end up making decisions that bump the price by a few pennies - but end up hurting the company in the long run.
Frontend app development is very similar in my eyes. You should always be aware of your code's performance. You certainly don't want to write code that will cause your app to run noticeably bad. But you also don't want to spend half of every sprint trying to micro-optimize every minute detail of your code.
If this all sounds terribly abstract, I'll try to give you some guidance on when you need to care about application performance - and when you shouldn't allow it to bog down your development.

Developer Trials
The first thing you need to keep in mind is that your code will (hopefully) be reviewed by others devs. This happens when you submit new code, or even when someone comes by months later and looks at what you've written. And many devs LOVE to nitpick your code for performance.
You can't avoid these "trials". They happen all the time. The key is not to get sucked into theoretical debates about the benchmark performance of a for loop versus the Array.prototype function of .forEach(). Instead, you should try, whenever possible, to steer the conversation back into the realm of reality.
Benchmarking Based Upon Reality
What do I mean by "reality"? Well, first of all, we now have many tools that allow us to benchmark our apps in the browser. So if someone can point out that I can shave a few seconds of load time off my app by making one-or-two minor changes, I'm all ears. But if their proposed optimization only "saves" me a few microseconds, I'm probably gonna ignore their suggestions.
You should also be cognizant of the fact that a language's built-in functions will almost always outperform any custom code. So if someone claims that they have a bit of custom code that is more performant than, say, Array.prototype.find(), I'm immediately skeptical. But if they can show me how I can achieve the desired result without even using Array.prototype.find() at all, I'm happy to hear the suggestion. However, if they simply believe that their method of doing a .find() is more performant than using the Array.prototype.find(), then I'm going to be incredibly skeptical.
Your Code's Runtime Environment
"Reality" is also driven by one simple question: Where does the code RUN??? If the code-in-question runs in, say, Node (meaning that it runs on the server), performance tweaks take on a heightened sense of urgency, because that code is shared and is being hit by everyone who uses the app. But if the code runs in the browser, you're not a crappy dev just because the tweak is not forefront in your mind.
Sometimes, the code we're examining isn't even running in an app at all. This happens whenever we decide to do purely academic exercises that are meant to gauge our overall awareness of performance metrics. Code like this may be running in a JSPerf panel, or in a demo app written on StackBlitz. In those scenarios, people are much more likely to be focused on finite details of performance, simply because that's the whole point of the exercise. As you might imagine, these types of discussions tend to crop up most frequently during... job interviews. So it's dangerous to be downright flippant about performance when the audience really cares about almost nothing but the performance.
The "Weight" Of Data Types
"Reality" should also encompass a thorough understanding of what types of data that you're manipulating. For example, if you need to do a wholesale transformation on an array, it's perfectly acceptable to ask yourself: How BIG can this array reasonably become? Or... What TYPES of data can the array typically hold?
If you have an array that only holds integers, and we know that the array will never hold more than, say, a dozen values, then I really don't care much about the exact method(s) you've chosen to transform that data. You can use .reduce() nested inside a .find(), nested inside a .sort(), which is ultimately returned from a .map(). And you know what?? That code will run just fine, in any environment where you choose to run it. But if your array could hold any type of data (e.g., objects that contain nested arrays, that contain more objects, that contain functions), and if that data could conceivably be of nearly any size, then you need to think much more carefully about the deeply-nested logic you're using to transform it.
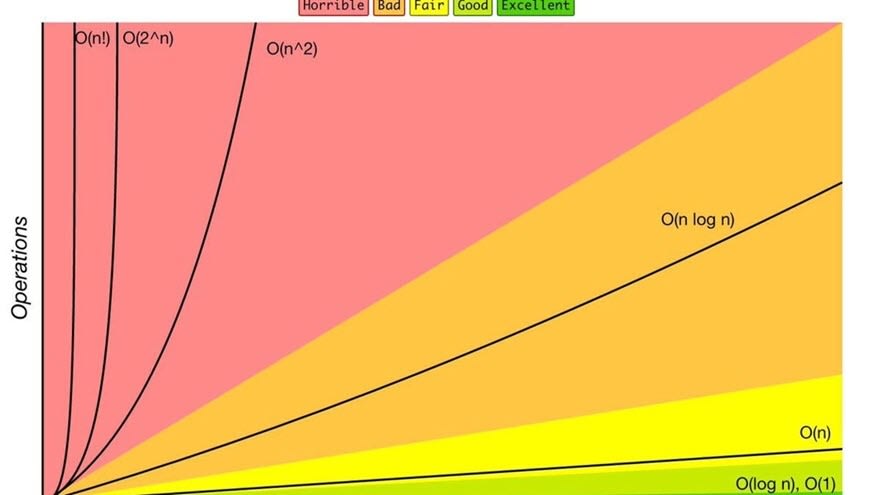
Big-O Notation
One particular sore point (for me) about performance is with Big-O Notation. If you earned a computer science degree, you probably had to become very familiar with Big-O. If you're self-taught (like me), you probably find it to be... onerous. Because it's abstract and it typically provides no value in your day-to-day coding tasks. But if you're trying to get through coding interviews with Big Tech companies, it'll probably come up at some point. So what do you do?
Well, if you're intent upon impressing those interviewers who are obsessed with Big-O Notation, then you may have little choice but to hunker down and force yourself to learn it. But there are some shortcuts you can take to simply make yourself familiar with the concepts.
First, understand the dead-simple basics:
O(1)is the most immediate time complexity you can have. If you simply set a variable, and then at some later point, you access the value in that same variable, this isO(1). It basically means that you have immediate access to the value stored in memory.O(n)is a loop.nrepresents the number of times you need to traverse the loop. So if you're just creating a single loop, you are writing something ofO(n)complexity. Also, if you have a loop nested inside another loop, and both loops are dependent upon the same variable, your algorithm will typically beO(n-squared).Most of the "built-in" sorting mechanisms we use are of
O(n log(n))complexity. There are many different ways to do sorts. But typically, when you're using a language's "native" sort functions, you're employingO(n log(n))complexity.
You can go deeeeeep down a rabbit hole trying to master all of the "edge cases" in Big-O Notation. But if you understand these dead-simple concepts, you're already on your way to at least being able to hold your own in a Big-O conversation.
Second, you don't necessarily need to "know" Big-O Notation in order to understand the concepts. That's because Big-O is basically a shorthand way of explaining "how many hoops will my code need to jump through before it can finish its calculation."
For example:
const myBigHairyArray = [... thousandsUponThousandsOfValues];
const newArray = myBigHairyArray.map(item => {
// tranformation logic here
});
This kinda logic is rarely problematic. Because even if myBigHairyArray is incredibly large, you're only looping through the values once. And modern browsers can loop through an array - even a large array - very fast.
But you should immediately start thinking about your approach if you're tempted to write something like this:
const myBigHairyArray = [... thousandsUponThousandsOfValues];
const newArray = myBigHairyArray.map(outerItem => {
return myBigHairyArray.map(innerItem => {
// do inner tranformation logic
// comparing outerItem to innerItem
});
});
This is a nested loop. And to be clear, sometimes nested loops are absolutely necessary, but your time complexity grows exponentially when you choose this approach. In the example above, if myBigHairArray contains "only" 1,000 values, the logic will need to iterate through them one million times (1,000 x 1,000).
Generally speaking, even if you haven't the faintest clue about even the simplest aspects of Big-O Notation, you should always strive to avoid nesting anything. Sure, sometimes it can't be avoided. But you should always be thinking very carefully about whether there's any way to avoid it.
Hidden Loops
You should also be aware of the "gotchas" that can arise when using native functions. Yes, native functions are generally a "good" thing. But when you use a native function, it can be easy to forget that many of those functions are doing their magic with loops under the covers.
For example: imagine in the examples above that you are then utilizing .reduce(). There's nothing inherently "wrong" with using .reduce(). But .reduce() is also a loop. So if your code only appears to use one top-level loop, but you have a .reduce() happening inside every iteration of that loop, you are, in fact, writing logic with a nested loop.

Readability / Maintainability
The problem with performance discussions is that they often focus on micro-optimization at the expense of readability / maintainability. And I'm a firm believer that maintainability almost always trumps performance.
I was working for a large health insurance provider in town and I wrote a function that had to do some complex transformations of large data sets. When I finished the first pass of the code, it worked. But it was rather... obtuse. So before committing the code, I refactored it so that, during the interim steps, I was saving the data set into different temp variables. The purpose of this approach was to illustrate, to anyone reading the code, what had happened to the data at that point. In other words, I was writing self-documenting code. By assigning self-explanatory names to each of the temp variables, I was making it painfully clear to all future coders exactly what was happening after each step.
When I submitted the pull request, the dev manager (who, BTW, was a complete idiot) told me to yank out all the temp variables. His "logic" was that those temp variables each represented an unnecessary allocation of memory. And you know what?? He wasn't "wrong". But his approach was ignorant. Because the temp variables were going to make absolutely no discernible difference to the user, but they were going to make future maintenance on that code sooooo much easier. You may have already guessed that I didn't stick around that gig for too long.
If your micro-optimization actually makes the code more difficult for other coders to understand, it's almost always a poor choice.

What To Do?
I can confidently tell you that performance is something that you should be thinking about. Almost constantly. Even on frontend apps. But you also need to be realistic about the fact that your code is almost always running in an environment where there are tons of unused resources. You should also remember that the most "efficient" algorithm isn't always the "best" algorithm, especially if it looks like gobbledygook to all future coders.
Thinking about code performance is a valuable exercise. One that any serious programmer should probably have, almost always, in the back of their mind. It's incredibly healthy to continually challenge yourself (and others) about the relative performance of code. In doing so, you can vastly improve your own skills. But performance alone should never be the end-all/be-all of your work. And this is especially true if you're a "frontend developer".