Deploy CockroachDB on the Public Cloud using Ansible

I've been casually using Ansible for a few years now. I use it mostly to facilitate the creation of demo clusters and workshop environments. In previous jobs, the standard was to create bash scripts for this type of automation. But bash scripts have a bad tendency to become long applications that are hard to read, maintain and expand in scope. Ansible instead scales and expands easily, and while it's certainly more difficult to get started, the benefits from using it appear very soon.
I never had the opportunity to learn Ansible for real DevOps work, still, I thought you might find useful to see how I can easily create a CockroachDB cluster on the public cloud. I have created an Ansible Collection and made it available for anyone to download and use.
Overview
In this blog post, I will demonstrate how to deploy a secured, kerberized, multi-cloud CockroachDB cluster using Ansible. This is helpful for testing, demonstrations, and to gain a broad understanding of the steps required for a real production deployment.
We create a 9 nodes cluster across 3 regions, with each region in a different cloud provider. We will create Load Balancers for each region, too.
Each region will also be setup with an App server, from which you will connect and run your SQL queries.
Additionally, we setup a MIT KDC server, for Kerberos authentication.
Below is the architecture diagram of the deployment.

Let's get started!
Note: I'm currently updating Ansible Role
cloud_instancethat I use to provision VMs in the public cloud, specifically, the modules used for Azure. Therefore, temporarily, we will use GCP instead of Azure. I will update this blog and remove this notice as soon as the Ansible Role has been updated.
(Optional) Create an Ansible Control Machine (ACM)
I run Ansible out of my work computer, so if you are already familiar with how Ansible works you don't need to create an ACM in the public cloud.
However, if this is your first time with Ansible and/or you are working with a Windows computer, it might be easier to reproduce the steps if you setup the ACM and follow along.
Spin up a t2.micro with Ubuntu 21.04, or similar instance in your preferred public cloud provider.
Ensure the AWS Security Group has a rule to only allow SSH traffic from your IP: we want to be sure nobody can access this VM as you will store the keys used to provision the cluster.
Once provisioned, ssh into the box and run below commands:
# ensure system is up-to-date, and install ansible + pip
$ sudo apt update
$ sudo apt upgrade -y
$ sudo apt install -y ansible python3-pip
# ensure you're using Ansible 2.10 or higher
$ ansible --version
ansible 2.10.5
config file = None
configured module search path = ['/home/ubuntu/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3/dist-packages/ansible
executable location = /usr/bin/ansible
python version = 3.9.5 (default, May 11 2021, 08:20:37) [GCC 10.3.0]
Good, your ACM is now ready to go!
Setup
In this section, we will download and configure the Ansible Collections required to deploy the cluster.
# create a directory for your work
mkdir cockroachdb
cd cockroachdb
Create a project specific Ansible config file, and install the Ansible Collections and their Requirements
cat - >ansible.cfg <<EOF
[defaults]
forks = 25
host_key_checking = False
stdout_callback = yaml
EOF
# Install the Ansible CockroachDB Collection at playbook level
ansible-galaxy collection install git+https://github.com/fabiog1901/cockroachdb-collection.git -p collections/
# Install the required Ansible Collections to the default location:
ansible-galaxy collection install -r collections/ansible_collections/fabiog1901/cockroachdb/requirements.yml
# install required pip packages for AWS, GCP, Azure
pip install -r ~/.ansible/collections/ansible_collections/amazon/aws/requirements.txt
pip install -r ~/.ansible/collections/ansible_collections/google/cloud/requirements.txt
pip install -r ~/.ansible/collections/ansible_collections/azure/azcollection/requirements-azure.txt
# copy the sample Playbooks in the CockroachDB Collection to our working directory
cp collections/ansible_collections/fabiog1901/cockroachdb/playbooks/* .
mkdir config
cp collections/ansible_collections/fabiog1901/cockroachdb/config/sample.yml config
Great, we've all the required Ansible components!
Now export the public cloud auth keys and start the SSH Agent, adding the ssh key to the agent
# export cloud provider keys
# AWS
export AWS_ACCESS_KEY_ID=AKIxxxxxxxxyyyyyzzzz
export AWS_SECRET_ACCESS_KEY=xxxxxxxyyyyyyyyyyzzzzzzzz
# For Google Cloud, it's not as easy so you need to sftp or copy-paste your service account file if
# you're using the cloud ACM
touch my-project.json
cat - >my-project.json <<EOF
{
"type": "service_account",
"project_id": "my-project",
"private_key_id": "xxxyyyzzzz",
"private_key": "-----BEGIN PRIVATE KEY-----\ ... -----END PRIVATE KEY-----\n",
"client_email": "workshop@my-project.iam.gserviceaccount.com",
"client_id": "8888",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/workshop%40cmyproject.iam.gserviceaccount.com"
}
EOF
chmod 400 my-project.json
export GCP_SERVICE_ACCOUNT_FILE=my-project.json
export GCP_AUTH_KIND=serviceaccount
export GCP_PROJECT=my-gcp-project
# for AZURE
export AZURE_SUBSCRIPTION_ID=xxxxxx-yyyyy-zzzzzz
export AZURE_AD_USER=xxxxyyyyzzzzz
export AZURE_PASSWORD='xxxxyyyyzzzz'
# Just like you did for GCP's service account file, sftp or copy-paste the private ssh key if
# you're using the cloud ACM
touch workshop.pem
cat - >workshop.pem <<EOF
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
EOF
chmod 400 workshop.pem
# start the ssh-agent and add the key.
# On my macbook, I just do `ssh-agent`.
# Below is the command on Ubuntu
eval $(ssh-agent)
ssh-add workshop.pem
# confirm the key was added with
ssh-add -l
The ssh key I've added here to the ssh-agent is the key used by Ansible to ssh into every VM. This is the private key part of the public key you've setup on the public cloud, see below for AWS and GCP:

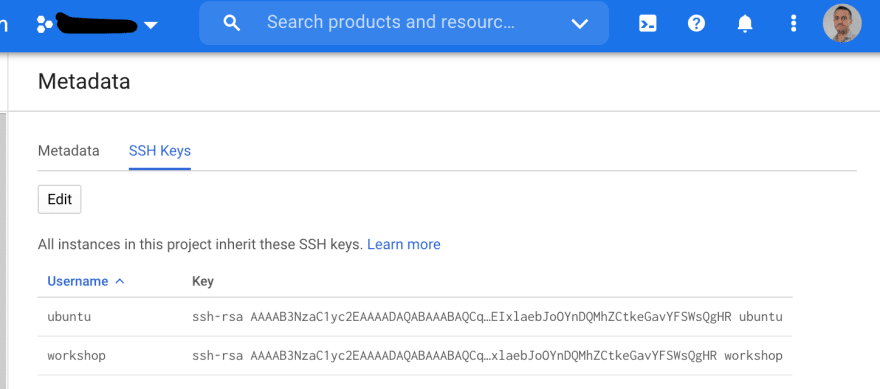
For simplicity, I use the same key for both clouds.
At this point you've all the tools you need to run the playbook.
What's missing are the details of you public cloud environments.
Configuration
Assumptions:
- you already have available, or know how to create, AWS VPCs, Subnets, Security Groups and their equivalent in GCP and Azure.
- you know how to request to increase your quotas, should you run into an error that points at quotas been exceeded.
- you know how to read the Ansible output to figure out and troubleshoot any possible errors. There are unfortunately too many variables to consider to ensure your public cloud env is similar to the one I use so I rely on your skills to overcome these issues.
Using vi or nano, open file config/sample.yml.
At line 5 of the file you'll find a variable called regions. Take some time to study this variable, as it's quite complex yet, hopefully, well organized.
This variable is a dictionary that holds the values of your VPC, subnets, Security Groups, etc.. You need to update the variable with your details.
If you prefer to use different regions then those listed, feel free to update or add more as you see fit. As long as the structure of the variables is the same, you will be fine.
For example, at line 9 you'll find the public_key_id mentioned previously, in this case, the key is called workshop.
Unless you choose to use different regions than those specified, you're done here. If you use different regions however, make sure you update variable infra accordingly.
At this point, your config file is setup to suit your cloud environment.
Run
You can now run the playbook. sample.yml is your deployment file, that is, the file that holds all information about what you want to deploy, similar in spirit to a Kubernetes deployment file.
The playbook tries for the most part to stay idempotent, so if it errors out for some silly mistake you know how to fix, it's safe to run it again and again.
ansible-playbook site.yml -e @config/sample.yml
If it completes successfully, the Playbook will print out the groups magic variable, which is very useful now that we want to login and review everything that got deployed.
TASK [PRINT GROUPS MAGIC VARIABLE] ********************************************
ok: [localhost] =>
msg:
[...]
app:
- 35.245.28.201
- 54.219.186.215
- 34.142.11.1
cockroachdb:
- 34.145.153.191
- 54.241.135.38
- 54.193.57.73
- 54.183.36.247
- 34.89.108.176
- 34.85.227.69
- 35.221.40.16
- 34.142.16.169
- 34.142.83.159
haproxy:
- 34.86.85.212
- 54.176.62.208
- 35.246.47.46
[...]
krb5_server:
- 34.66.230.216
Take notice of groups cockroachdb, app, haproxy and krb5_server. This output doesn't list the region where the VM is located, so you might have to look it up from the AWS or GCP Console for those details.
Review
On your browser go to port 8080 on any or all of your haproxy servers to access the CockroachDB Console. In this example I head out to https://34.86.85.212:8080.
You need to accept the untrusted certificate presented (remember, this is a secure cluster with a self-signed cert whose CA is not recognized by the browser, see the Note at the bottom for more details).

Login with user fabio and password cockroach.
You have specified these details in the config/sample.yml file under section APPLICATION in the dbusers variable, and have created and granted admin privileges in the last 2 Tasks of Playbook application.yml.

Great, your 9 nodes, secure cluster is up!
Now, let's login into the SQL prompt as root user.
Pick any of the CockroachDB servers (here I picked the first of the list, 34.145.153.191), and ssh into the box.
# from the ACM, ssh into cockroachdb node
ssh ubuntu@34.145.153.191
Then, login as user root using the root cert and root key, which are located at /var/lib/cockroach/certs.
$ sudo cockroach sql --certs-dir=/var/lib/cockroach/certs
#
# Welcome to the CockroachDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
# Server version: CockroachDB CCL v21.1.5 (x86_64-unknown-linux-gnu, built 2021/07/02 03:57:09, go1.15.11) (same version as client)
# Cluster ID: adc08ee1-8805-4341-ab36-a87984332b26
# Organization: Workshop
#
# Enter \? for a brief introduction.
#
root@:26257/defaultdb> SHOW DATABASES;
database_name | owner | primary_region | regions | survival_goal
----------------+-------+----------------+---------+----------------
defaultdb | root | NULL | {} | NULL
postgres | root | NULL | {} | NULL
system | node | NULL | {} | NULL
(3 rows)
Time: 221ms total (execution 221ms / network 0ms)
root@:26257/defaultdb> SHOW LOCALITY;
locality
--------------------------
region=us-east4,zone=a
(1 row)
Time: 2ms total (execution 1ms / network 0ms)
root@:26257/defaultdb> SHOW USERS;
username | options | member_of
-----------+---------+------------
admin | | {}
app | | {admin}
fabio | | {admin}
root | | {admin}
(4 rows)
You can also use the full ODBC URL to login
sudo cockroach sql --url "postgresql://root@localhost:26257/defaultdb?sslmode=require&sslrootcert=/var/lib/cockroach/certs/ca.crt&sslcert=/var/lib/cockroach/certs/client.root.crt&sslkey=/var/lib/cockroach/certs/client.root.key"
Next, let's login as user fabio.
We have configured the cluster to use Kerberos, and are permitting connection to the cluster using Kerberos users only via the HAProxies, that is, you can't point to a CockroachDB node directly (this was instructed in the Ansible Playbook).
Ssh into any of the App Servers, then, at the prompt:
$ # the kerberos password was set in config/sample.yml
$ # with variable 'krb5_principals',
$ # under section PLATFORM > MIT KDC.
$ kinit fabio
Password for fabio@FABIO.LOCAL:
$ # verify the ticket was created successfully
$ klist
Ticket cache: FILE:/tmp/krb5cc_1000
Default principal: fabio@FABIO.LOCAL
Valid starting Expires Service principal
08/13/21 11:53:46 08/14/21 11:53:46 krbtgt/FABIO.LOCAL@FABIO.LOCAL
renew until 08/20/21 11:53:46
$ # connect to the database
$ # take note of parameter 'krbsrvname=cockroach'
$ # which is the SPN we created with Ansible
$ cockroach sql --url "postgresql://fabio@212.85.86.34.bc.googleusercontent.com:26257/defaultdb?sslmode=require&sslrootcert=ca.crt&krbsrvname=cockroach"
#
# Welcome to the CockroachDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
# Client version: CockroachDB CCL v21.1.7 (x86_64-unknown-linux-gnu, built 2021/08/09 17:55:28, go1.15.14)
# Server version: CockroachDB CCL v21.1.5 (x86_64-unknown-linux-gnu, built 2021/07/02 03:57:09, go1.15.11)
# Cluster ID: adc08ee1-8805-4341-ab36-a87984332b26
# Organization: Workshop
#
# Enter \? for a brief introduction.
#
fabio@34.86.85.212:26257/defaultdb> SHOW LOCALITY;
locality
--------------------------
region=us-east4,zone=c
(1 row)
Time: 3ms total (execution 1ms / network 2ms)
fabio@34.86.85.212:26257/defaultdb> SELECT version();
version
--------------------------------------------------------------------------------------------
CockroachDB CCL v21.1.5 (x86_64-unknown-linux-gnu, built 2021/07/02 03:57:09, go1.15.11)
(1 row)
Time: 2ms total (execution 0ms / network 2ms)
fabio@34.86.85.212:26257/defaultdb> SELECT now();
now
---------------------------------
2021-08-13 11:54:49.551574+00
(1 row)
Time: 2ms total (execution 0ms / network 2ms)
Validate by destroying the ticket and reattempt connection
$ kdestroy
$ cockroach sql --url "postgresql://fabio@212.85.86.34.bc.googleusercontent.com:26257/defaultdb?sslmode=require&sslrootcert=ca.crt&krbsrvname=cockroach"
#
# Welcome to the CockroachDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
ERROR: pq: kerberos error: open /tmp/krb5cc_1000: no such file or directory
Failed running "sql"
As expected, we got denied.
Finally, our last test involves bypassing Kerberos by authenticating using cert+key.
We specified that we allow user app to authenticate using this mechanism in the "hba.conf" file using this SQL line, in application.yml:
SET cluster setting server.host_based_authentication.configuration = '
host all app all cert-password
host all all all gss include_realm=0';
Which says, in plain English: "accept either a certificate or a password as authentication mechanism for user app; accept Kerberos auth for any user".
The certificate and key for user app should be in the home folder already, check with ls.
$ ls -l client.app*
-rw-r--r-- 1 root root 4000 Aug 10 22:04 client.app.crt
-rw------- 1 root root 1675 Aug 10 22:04 client.app.key
Now, login using these certs
$ cockroach sql --url "postgresql://app@34.86.85.212:26257/defaultdb?sslmode=require&sslrootcert=ca.crt&sslcert=client.app.crt&sslkey=client.app.key"
#
# Welcome to the CockroachDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
# Client version: CockroachDB CCL v21.1.7 (x86_64-unknown-linux-gnu, built 2021/08/09 17:55:28, go1.15.14)
# Server version: CockroachDB CCL v21.1.5 (x86_64-unknown-linux-gnu, built 2021/07/02 03:57:09, go1.15.11)
# Cluster ID: adc08ee1-8805-4341-ab36-a87984332b26
# Organization: Workshop
#
# Enter \? for a brief introduction.
#
app@34.86.85.212:26257/defaultdb> SELECT gen_random_uuid() FROM generate_series(1, 10);
gen_random_uuid
----------------------------------------
e5af9bdd-4e43-44b4-8a05-79b183adf33e
b59922b8-37ae-4c7a-8de5-7012b0b3c3a5
3b14db65-321d-4bd8-8018-2777a436e27c
a8b01ae3-2326-4e72-ad40-d260fa3b0876
9aaa7a29-8615-4f67-81a6-efea50b62eb8
15774a59-9ca6-456b-974c-db2965cbb36a
a2f748a1-fca1-4e46-8ea8-6760bf2dc8d1
0526fd48-ac5c-471a-be92-7e51e71e397e
b0bc6785-e110-45b5-8fa9-8f234bfcbbe7
6622fb33-d66e-4858-88a1-9b5c75ccbf67
(10 rows)
Time: 2ms total (execution 1ms / network 2ms)
Perfect, this concludes our testing!
Clean up
You can destroy every VM by simple set variable exact_count to 0 (zero), however, it's far simpler to delete all VMs from the AWS/GCP console. Each VM has been tagged with deployment_id and owner, so it's easy to filter out the VMs for this deployment.
Acknowledgments
I would like to thank the Cloudera Professional Services organization for the krb_client and krb_server roles, which are included in the Collection but were taken from an early work and are currently available here in their latest version.
Special thanks go to Webster Mudge, who initially designed the high level architecture of the Collection's Playbooks (infrastructure, platform, application).
Reference
CockroachDB
CockroachDB Docs
fabiog1901/cockroachdb-collection