Design a Web Crawler

What is a web crawler?
Search engines like Google need to find and index new web pages frequently so that users can quickly fetch the latest information. Record labels need to monitor for cases of copyright and trademark infringements. These are just some of the use cases for a web crawler.
The Scenario
Let's consider a use case where we will need to process 1 billion web pages per month and store the pages content for up to 5 years.
Estimate the Storage Requirements
The number of queries for web pages per second (QPS):
1 x 109 pages / 30 days / 24 hours / 3600 seconds = 400 QPS
There can be several reasons why the QPS can be above this estimate. So we calculate a peak QPS:
Peak QPS = 2 * QPS = 800 QPS
The average web page size we will use is:
500 kb
The storage required per month for storing pages:
1 x 109 pages X 500 kb = 500 tb
The storage required to store pages for 5 years:
500 tb X 12 months X 5 years = 30 pb (petabytes)
High Level Design
Below is what the logical flow will look like at a high level. We will then cover each step in some detail.
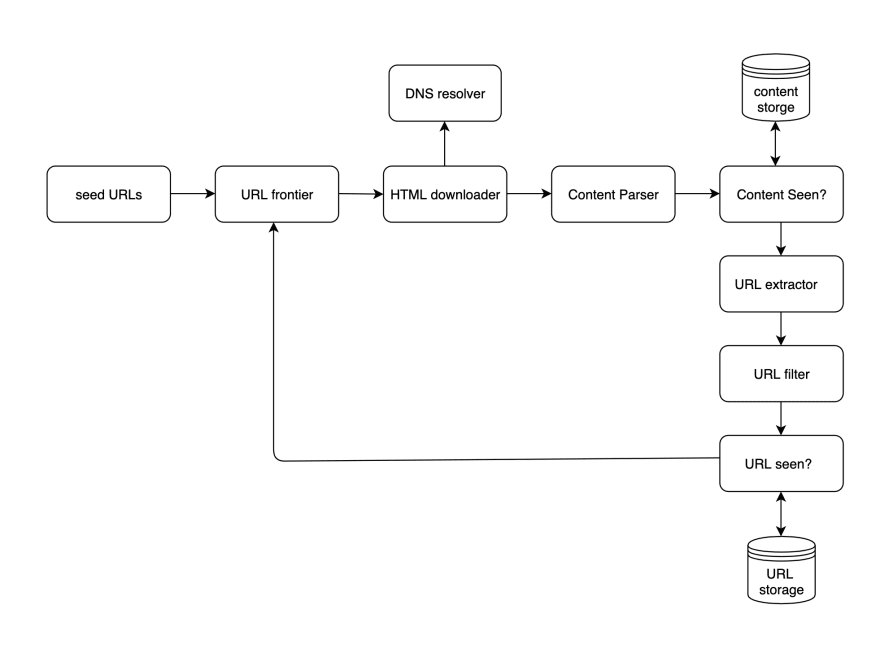
Seed URLS
The seed urls are a simple text file with the URLs that will serve as the starting point of the entire crawl process. The web crawler will visit all pages that are on the same domain. For example if you were to supply www.homedepot.com as a seed url, you'l find that the web crawler will search through all the store's departments like www.homedepot.com/gardening and www.homedepot.com/lighting and so on.
The seed URLs chosen depend on your use case. If you were a record label creating a crawler to find all instances of copyright infringement, you might use seed URLs were you are most likely to find copyright infringements like www.soundcloud.com and www.youtube.com.
URL Frontier
You can think of this step as a first-in-first-out(FIFO) queue of URLs to be visited. Only URLs never visited will find their way onto this queue. Up next we'll cover two important considerations for the URL frontier.
- Politeness: Our web crawler needs to avoid sending too many consecutive or parallel requests to the same server, or else you have the possibility of causing a denial-of-service(DOS) attack. In order to avoid flooding the host server with requests, we can implement a strategy where all requests to a particular host are processed by only one process at a time. This avoids parallel requests to the same server.
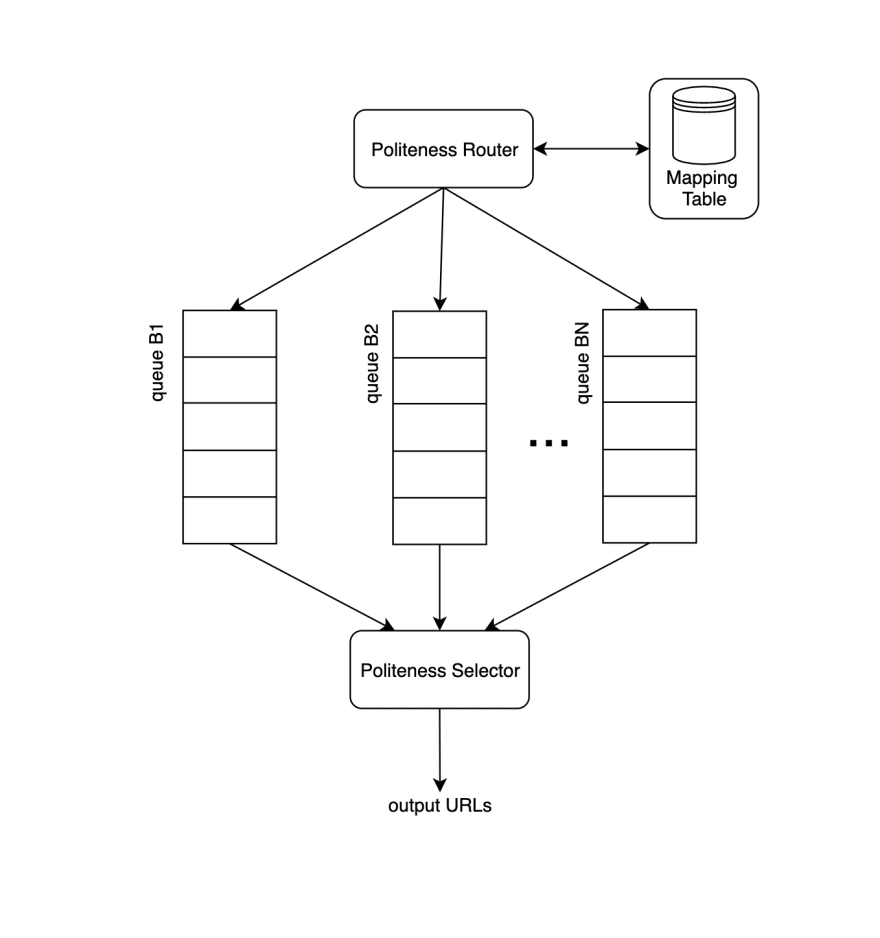
The above design shows the components that manage politeness. The mapping table stores a mapping between host domain (e.g. www.homedepot.com) to a single and specific queue. The queue router uses that mapping to send URLs to the appropriate queue. Each queue (1,2....N) then contains URLs from the same host. Each download process is mapped to queue and receives one URL at a time. A delay between each download task can also be added.
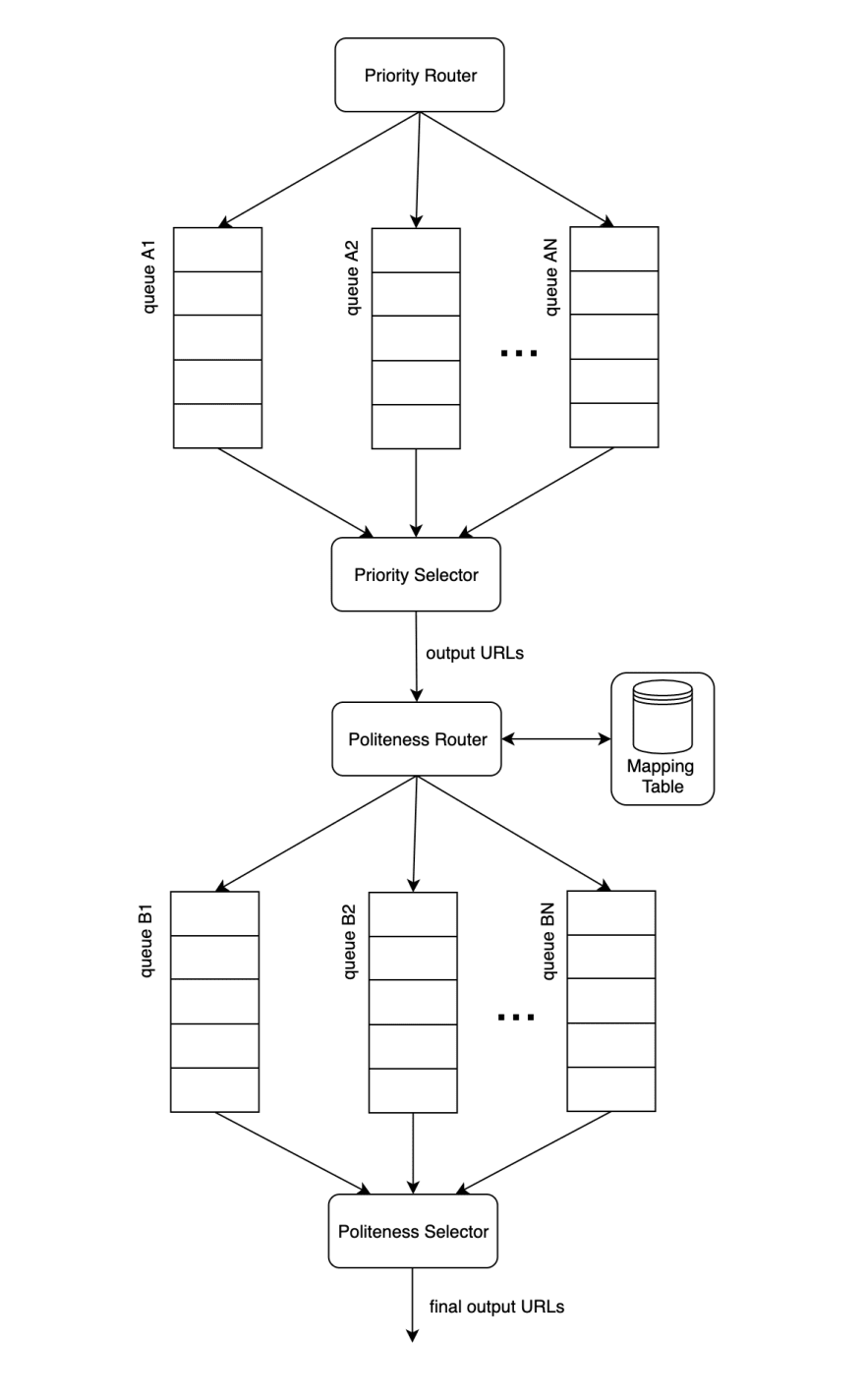
- Priority: Not all web pages have the same level of importance. A new post on a reddit group has less priority than a new post on the associated press, for example. So we need a component in our workflow to manage priority. We'll use the same design that we used for the politeness component, except in this case the different queues represent different priority levels. And the queue selector is responsible for selecting URLs from the high priority queue more often. We'll then put these two queues in sequence. First the URLs will be placed on priority queues, then placed on politeness queues. See design below.
HTML Downloader
Given a URL, this step makes a request to DNS and receives an IP address. Then another request to the IP address to retrieve an HTML page.
There exists a file on most websites called robots.txt that is used by crawlers as a guide to which pages a crawler is allowed to parse. See below for a snippet of what the https://www.apple.com/robots.txt file looks like. Before attempting to crawl a site, we should make sure to check for this file and follow its rules. This robots file is also a good candidate for cacheing to avoid duplicated downloads.
Disallow: /*retail/availability*
Disallow: /*retail/availabilitySearch*
Disallow: /*retail/pickupEligibility*
Disallow: /*shop/sign_in*
Disallow: /*shop/sign_out*
Disallow: /*/shop/1-800-MY-APPLE/*
Up next we'll cover a few performance optimizations for the HTML downloader
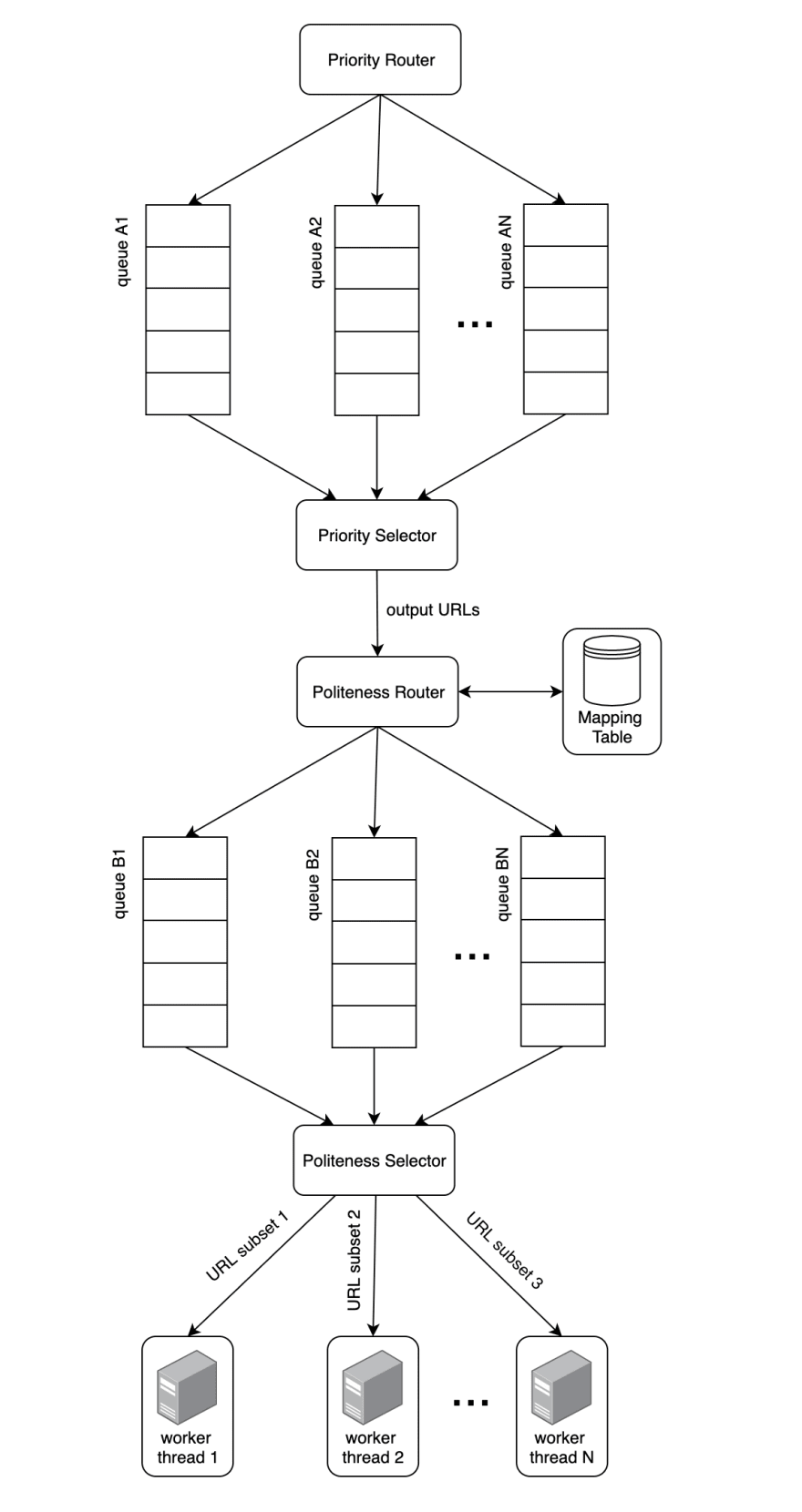
- Distributed Crawl: Like most strategies to achieve high performance, distributing tasks among several servers instead of one is ideal. We'll have more than one server in the HTML Downloader be responsible for making HTTP requests given a subset of URLs. See below for an updated diagram of our URL frontier plus a distributed HTML downloader.
Cache DNS Resolver: An average response time for a DNS request can be between 10ms - 200ms. When one thread makes a request to DNS, the others are blocked until the first request is finished. So maintaining our own DNS cache(in memory or separate db) is an effective technique for speed optimization. This cache can be updated periodically using a simple cron job.
Locality: Choose to deploy the servers geographically. When the HTML Downloader server is located closer to website hosts this can significantly reduce download time. This can also apply to all other components in the workflow: crawl servers, cache, queue, storage, etc.
Short timeout: Some web servers may respond slower than others, and we don't want our crawl to be slowed down by this. So it's a good idea to set a maximal wait time on the HTML downloader. If a host does not respond within a predefined time, the downloader will skip and move on to other pages.
DNS Resolver
A URL needs to be translated into an IP address by the DNS resolver before the HTML page can be retrieved.
Content Parser
Any HTML page on the internet is not guaranteed to be free of errors or erroneous data. The content parser is responsible for validating HTML pages and filtering out malformed data.
Content Seen?
With billions of pages the crawler needs to search through, we want to be sure we aren't duplicating our work by eliminating pages that have already been processed in the past. This step will check if the HTML content is already in storage, and if it is, will discard. It will do this by making a query to the content storage database.
Content Storage
A storage system for HTML. This can be a traditional relational database. We can improve the speed of checking for duplicate content by storing only a hash or a checksum of an HTML page, instead of having to parse and store an entire HTML page.
URL Extractor
This step parses over HTML and extracts new URLs to process. For example, below is a snippet of HTML from Apple's website. The URL Extractor will find href values and create full URLs.

URL Filter
This step is responsible for excluding certain content types like PDFs or JPGs, and also URLs on blacklists we may have. It finds these content types by lookin for file extensions in URLs.
URL Seen
This step keeps track of URLs that have already been visited before, or that already exists in the URL Frontier. It accomplishes this by checking if the URL is already in the URL storage database. This helps reduce duplicate work and possible infinite loop conditions.
This post is an extract from a book titled "System Design Interview – An insider's guide" By Alex Xu.