GitOps Benefits and Considerations

GitOps. The term appears everywhere, but what are its benefits? And is it as difficult as it sounds? Well, GitOps is a pretty easy paradigm to integrate with your current processes. However, my saying it is “easy” doesn’t help you decide whether you want to adopt it or not. So, let’s talk about it.
This post will briefly discuss common software delivery challenges, DORA metrics and what they are, how GitOps can help with those metrics, and what to consider if you would like to adopt it.
Software Delivery Challenges
Most existing processes for infrastructure configuration management face challenges like failed deployments, poor infrastructure design, server outages, etc. Some common challenges are:
- “Eventual Consistency” or lack of configuration consistency in your environment. For example, how do you know if “System A” and “System B” match? The actual configuration and a declared one can alter and change when using manual processes, even when using a centralized configuration.
- No idea as to how or where an application is running. Implicit infrastructure, its state, and configuration. This sometimes entails a full-scale investigation to determine the “how” and the “where.”
- Failed deployments relying on a disaster recovery strategy. With manual or semi-manual processes, disaster recovery requires a strict process that teams are disciplined to tackle, which isn’t always reliable—resulting in unplanned downtime that takes away from developers’ skills and productivity.
- Missing documentation or unknown development history. It can be challenging to figure out how some applications were built initially and who managed them.
- Relying on a system’s previous state for success. This can be unpredictable, which affects the stability and success of a project.
Or, to state these challenges in another way: inconsistent configurations can lead to failed deployments, leading to revenue loss. GitOps can help with all of these challenges. We are going to dive into GitOps more in a bit. But first, let’s talk about DORA metrics and why they matter.
DevOps and DORA metrics
DevOps is a collaboration paradigm, and sometimes it is mistaken for being too abstract or too generic. In an effort to quantify the benefits of adopting DevOps, Dora Research (acquired by Google in 2018) has introduced four key metrics that define specific goals for improving the software lifecycle in companies that are interested in DevOps.
These four key metrics and their organizational effects have been published as part of the “State of DevOps” reports since 2014. The reports include a survey (with more than 32,000 industry professionals in the last years) that categorize the organizations that responded. These categorizations or performance levels are:
- Elite performers (companies that have fully adopted DevOps and have exceptional results in the four metrics)
- High performers (companies with excellent results in the four metrics)
- Medium performers (companies with some positive results)
- Low performers (all other companies)
The researchers responsible for the survey apply these different categorizations by examining how teams develop, deliver, and operate software systems, and then segmenting respondents into four performance clusters: elite, high, medium, and low performers.
The 4 Key DevOps Metrics + 1
The four metrics of software delivery performance are:
- Deployment Frequency (DF) – How frequently a team successfully releases to production, e.g., daily, weekly, monthly, yearly.
- Lead Time for Changes (MLT) – The median amount of time for a commit to be deployed into production.
- Time to Restore Service(s) (MTTR) – How long it takes an organization to recover from a failure in production. For a failure, the median amount of time between the deployment that caused the failure and the remediation. The remediation is measured by closing an associated bug/incident report.
- Change Failure Rate (CR) – The number of failures per the number of deployments. For example, if there are four deployments in a day and one causes a failure, that is a 25% change failure rate.
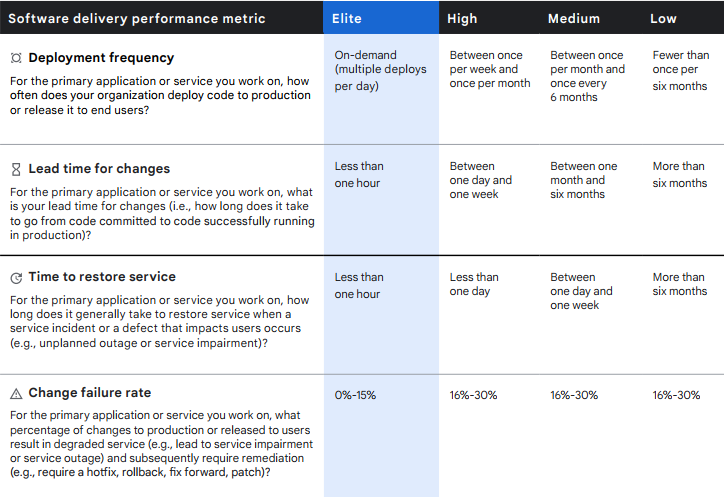<br>
ance-metric.png](https://res.cloudinary.com/practicaldev/image/fetch/s--l4A5Cq0l--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://codefresh.io/wp-content/uploads/2022/04/2021-State-of-DevOps-Software-delivery-performance-metric.png)
2021 State of DevOps – Software Delivery Performance Metric
Since 2018, a fifth metric around operational performance has also been included: reliability.
- Reliability – the degree to which a team can keep promises and assertions about the software they operate. Reliability was chosen so that availability, latency, performance, and scalability are more broadly represented.
Companies’ DevOps teams ranked as elite or high-performing in these five categories tend to have outstanding performance around market share and profits.
What is GitOps?
What exactly is GitOps? If you are not familiar with GitOps, head over to https://opengitops.dev, which is the official page of the GitOps working group. In short, GitOps is a set of standards and best practices that can be applied to application configuration and delivery, all the way to infrastructure management. GitOps is not a tool but works by relying on a single source of truth (typically Git) for declarative applications and infrastructure. The principles of GitOps are the following:
- The system is described in a declarative manner.
- The definition of the system is versioned and audited. This tends to be Git though it is not limited to it.
- A software agent automatically pulls the Git state and matches the platform state.
- The state is continuously reconciled. This means that any changes in Git should also be reflected in the system.
You will usually see GitOps paired with Kubernetes, though Kubernetes is not necessarily required. You can use GitOps to build pipelines, provision clusters, manage configurations, and much more.
Why GitOps is beneficial for DORA metrics
DORA metrics are great, especially when demonstrating critical areas for improvement to organizations. However, while organizations know about the metrics, it can be tough to have good performance numbers there. Adopting GitOps principles can help tackle these issues.
For example, because GitOps adds a structure of repeatability to your organization’s different environments, you can reduce MTTR and the change failure rate. This is because you now have a declarative reference architecture in place of your entire system. You also eliminate delivery as the last step in your Continuous Integration (CI) pipeline because of synchronization. That synchronization also means because you use Git for your systems’ versioning, you can now ensure that your deployments match your desired state. All of this combined means your MTTR is significantly reduced from days or hours to just minutes.
Also, you now have more frequent releases because you are using continuous deployment, which translates into increased speed and productivity. This increased speed and productivity translate into happier customers because of the potential for new features or functionality due to decreased turnaround time.
Know what is deployed where
Imagine having a magic wand that handles your deployments. GitOps can do that for you.Some CI tools follow an authoritative or ad-hoc approach and use things like custom kubectl scripts to deploy. The urge to change or edit something manually in environments is significant – it is perceived as quicker or easier. So, for example, you may have “cowboy deployments” or “cowboy engineering” where your DevOps team may be performing manual changes to the cluster. But when this happens, you have no idea what’s going on since those changes aren’t recorded anywhere, and the modifications can be pretty delicate.GitOps gets rid of those manual changes because whatever agent you’re using is in charge of the deployment. The deployment process or synchronization is a consolidation of whatever your current cluster state is to the desired state. The agent is also in charge of monitoring. Because of this, things are alike and in sync.
Faster deployments and rollbacks
There are times when you or a colleague may want to know, “What are the current deployment versions in environments A and B?” or “Is it possible to roll back to version XYZ?” When using a traditional CI/CD solution, these questions may be tough to answer because any number of ad-hoc patches, hotfixes, or other changes may have occurred since the initial deployment.
However, using GitOps, things are a bit simpler. Your Git repository will be able to tell you what deployments are in the cluster because your commit history can pretty much work as your cluster deployment history. The state of your cluster should look very similar to your latest git commit.
Rollbacks are also easier with GitOps. Things are more “hands-on” when working with traditional CI/CD. With conventional CI/CD, you have to research your deployment pipeline to find the correct version of what you need and then manually trigger it. With GitOps, this is not the case, as you only need to perform a reset in Git, and once things are synchronized, the cluster will reflect the necessary changes. Or, depending on what agent you are using, you could do something as simple as selecting the appropriate Git release and let the synchronization process handle the rest.
No configuration drift
Configuration drift is usually due to manual changes and updates across an organization’s environments. It is a problem that existed even with traditional Virtual Machines and has plagued production deployments long before Kubernetes appeared on the scene. The more environments you have and the longer your configuration drift is present, the more crucial things will become.
Remember when I mentioned monitoring earlier? Well, even though your agent’s sync process is crucial for performing the initial deployment of your application, one of the true strengths is the continuous monitoring of both states (cluster and Git) after the deployment takes place. The reconciler takes care of eliminating configuration drift by staying true to ONLY to the Git state. This uni-directional reconciliation is vital for solving configuration drift which is a widespread issue in organizations with large numbers of deployment targets.
If you would like to get an idea of how your team or organization’s software delivery performance compares to the rest of the industry, you can take the DORA “DevOps Quick Check” here.
Considerations for Adopting GitOps
There are two things to consider when deciding whether or not to embrace GitOps:
- You need to have a CI in place already
- You need a GitOps Agent
The first one is simple. If you already have a CI solution in place, keep using what you have. So, let's tackle the second.
If you need a GitOps agent, Argo CD is a great choice. Argo CD is a popular deployment solution for Kubernetes. When following a GitOps deployment pattern, Argo CD makes it easy to define a set of applications with their desired state in a repository and where the deployment should happen. After a deployment, Argo CD continuously monitors a Git repository with Kubernetes manifests and listens for commit events.
When a commit happens (usually one that updates the versions of the image artifacts), Argo CD starts a “synchronization” process responsible for bringing the cluster configuration to the same state as described in Git.
When the sync process is complete, we know that the application configuration is the same as the Git manifests.
The Argo CD deployment process is the embodiment of the core ideas behind GitOps that we discussed at the beginning:
- All application configuration is stored in Git (usually in a separate repository than the source code)
- Deployments are happening in a “pull” manner where the cluster is fetching manifests from Git (instead of traditional solutions where updates are “pushed” to the cluster)
- A deployment is a uni-directional reconciliation process between the two states (what is described in Git versus what is deployed in the cluster)
- Even though the sync process is vital for performing the initial deployment of the application, one of the true strengths of Argo CD is the continuous monitoring of both states (cluster and Git) after the deployment takes place. This continuous monitoring is essential for solving configuration drift – a common issue in organizations with a considerable number of deployment targets.
To clarify: your CI will stay the same. Nothing is changing except GitOps making things simpler. You no longer have to do certain things manually. If you were using Git? Continue to use Git. If you were using Kubernetes? Continue using Kubernetes. GitOps is less painful than you may imagine, and you are not starting over from scratch. Things are now streamlined.
You can learn how to get started with Argo CD here and read about Argo CD best practices here.
Conclusion
I mentioned earlier that GitOps was not just for Kubernetes. And that’s true! Kubernetes isn’t a requirement. GitOps can absolutely integrate with other deployment pipelines or infrastructure, including containers and VMs.
GitOps is also not just for applications. You can also use it with infrastructure toolings such as Terraform or Crossplane. If it is transactional, can be described declaratively, and Infrastructure-as-Code (IaC) tools are available, you can use GitOps in your environment.
Hopefully, now that you’ve learned more about GitOps you can find ways to introduce this paradigm to your workflow, whether it’s containerizing your application or adding your configuration to your repository. By doing so, you’ll be in good company: CapitalOne, Intuit, Tesla, Red Hat, Google, Codefresh, and many others are using Argo and GitOps to eliminate challenges in their environments. And if you’d like to learn more about how Codefresh has embraced GitOps or get started on your GitOps journey, you can try out the free Community Edition here.